
J’ai reçu il y a quelques mois un document de travail que mon interlocuteur avait écrit sur un fichier avec une extension « .md », un fichier écrit en Markdown ! J’étais ravi qu’en dehors de documentations de logiciels certains utilisent Markdown (le document était un contrat). Mais qu’est-ce que le markdown?
Kezako
Markdown est une syntaxe de balisage créée par John Grubber en 2004. Très utilisée dans la documentation de logiciel, notamment toute la documentation Github, Gitlab, Mantis, etc. Markdown a la particularité d’être très simple à rédiger avec initialement un nombre assez limité mais souvent suffisant de « markups », simple à lire même sans conversion.
Les plus pour le PLM
Historiquement, le PLM a été marqué par la complexité de gérer du diff dans des modèles de CAO (en opposition avec des developments logiciels, où le diff pouvait se faire par fichier voir de manière plus fine, ligne par ligne. J’en parle dans mon dernier article sur le « branch & merge »). Ce problème n’a pas encouragé les éditeurs à stocker les informations par incréments mais plutôt par copies. On le voit sur la plupart des solutions PLM, une génération, itération ou version d’un objet c’est avant tout un nouvel enregistrement dans l’outil de stockage utilisé.
Markdown (ou autre language du même type) facilite cette gestion d’incrément. On retrouve un peu le même système dans des solutions telles que wikipedia.
Donc lorsqu’on édite un document, l’usage d’un format tel que markdown avec un outil de gestion de source vous apporte la même flexibilité et traçabilité dont les développeurs logiciels bénéficient. Le document peut être un document texte, mais le texte peut-être une description de CAO ou autre élément technique.
Exemple: Jeux de données Rover de la nasa
Récupéré dans le jeux de données Open Source de la nasa, voici un extrait de documentation rédigé en markdown avec l’aperçu dans l’application « Typora« .

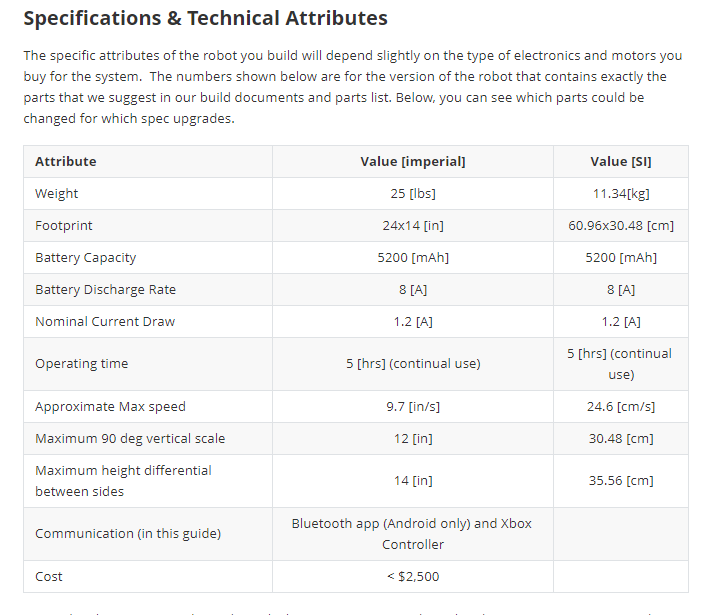
Dans ce cas je trouve personnellement dommage la façon dont le tableau est renseigné. J’aurai préféré une séparation format, données.
Un usage restreint sans granularité
La conséquence d’un tel format est que cela s’utilise largement comme un blob de données. Un blob de données simple à gérer en configuration mais cependant avec aucune granularité d’un point de vue PLM. On ne peut pas réutiliser une partie d’un document dans un autre document. Cela réaliserait directement un doublon
Ma conclusion
J’aime beaucoup la simplicité d’un tel language qui s’intègre très bien avec des outils de gestion de repository comme Git. D’ailleurs les documentations sur github sont largement faites avec ce language. L’édition reste encore souvent reservée à un public technnique sauf si vous utilisez un outil tel que typora. Mais même avec un tel outil, la partie gestion des modifications nécessite largement de passer par un outil de gestion de repository, encore une fois assez technique. Une startup française répond à cette problématique en réalisant une gestion de document basée sur Git. Je vous invite à tester leur solution :

Partager :